
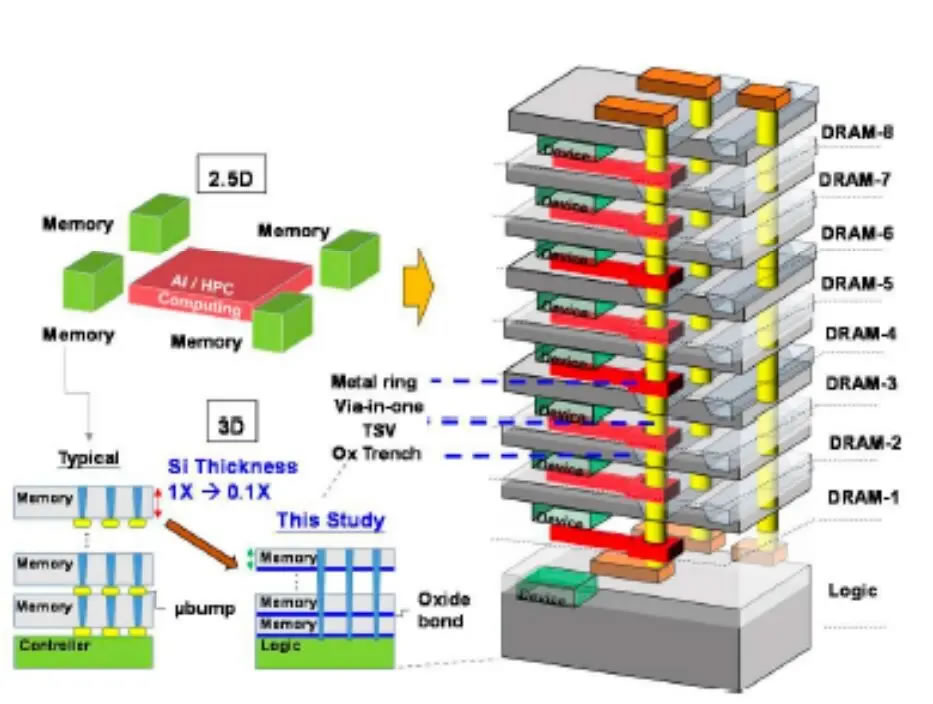
Intel et SoftBank, via leur coentreprise Saimemory, travaillent sur une nouvelle architecture mmoire qui pourrait faire parler delle dans le petit monde de lIA. Son nom : HB3DM. Derrire cette appellation se cache une mmoire empile en 3D, base sur une approche baptise Z-Angle Memory, avec une intgration verticale de plusieurs dies grce des techniques de hybrid bonding. Lobjectif est simple : offrir une bande passante maximale dans un encombrement rduit.
Contrairement aux approches classiques, qui cherchent souvent augmenter la capacit mmoire, cette solution vise avant tout le dbit. Et dans le domaine de lIA, notamment pour les acclrateurs, la bande passante est devenue un nerf de la guerre. Les GPU et autres puces spcialises ont besoin dalimenter leurs units de calcul trs haute vitesse, et la mmoire peut rapidement devenir un goulet dtranglement.

5.3 To/s de bande passante par module
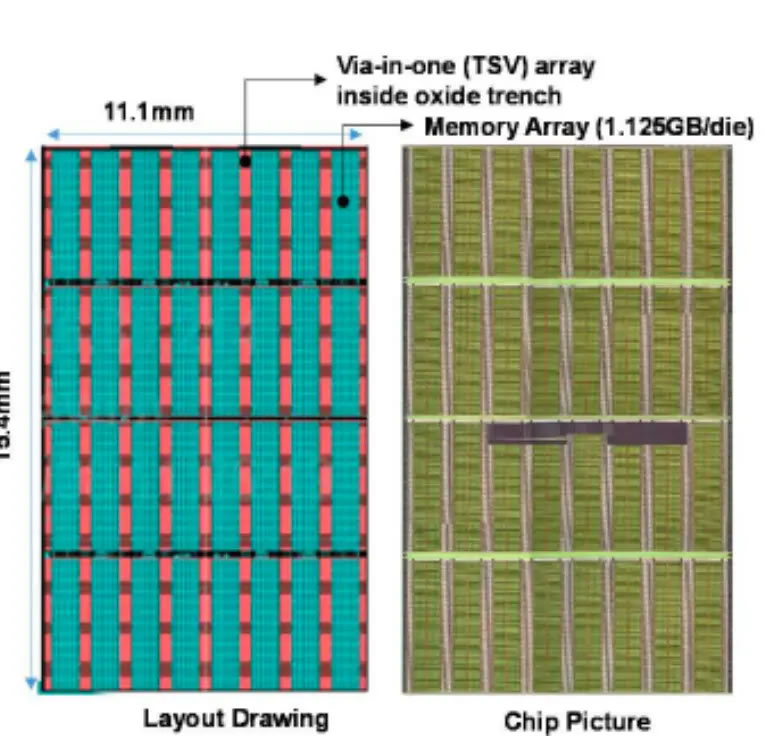
La premire gnration de HB3DM reposerait sur une configuration neuf couches, avec un die logique la base et huit couches de DRAM empiles au-dessus. Chaque couche intgrerait environ 13 700 TSV, ces interconnexions verticales qui permettent de faire communiquer les diffrents niveaux de la pile mmoire. Grce cette densit dinterconnexion, la bande passante atteindrait environ 0.25 Tb/s par mm.
Avec une taille de die estime 171 mm, cela donnerait une bande passante totale denviron 5.3 To/s par module. Un chiffre particulirement impressionnant, surtout si lon compare cette approche la HBM4, qui reste aujourdhui la rfrence attendue pour les futures gnrations dacclrateurs IA.

Moins de capacit, mais beaucoup plus de dbit
Le revers de la mdaille, cest la capacit. Chaque couche de DRAM offrirait environ 1.125 Go, pour un total denviron 10 Go par module. Cest nettement moins que la HBM4, qui peut monter jusqu 48 Go par stack. La HB3DM ne semble donc pas chercher remplacer directement la HBM dans tous les usages, mais plutt viser des charges de travail trs spcifiques, o le dbit prime sur la capacit.
On pense notamment certains scnarios dinfrence IA, au calcul intensif ou des charges o le dplacement rapide des donnes est plus important que le volume total stock. Reste encore plusieurs inconnues, notamment sur la consommation, la latence, mais aussi la production. Intel fabriquera-t-il cette DRAM en interne ou passera-t-il par des acteurs spcialiss ? Pour le moment, mystre. Plus de dtails sont attendus lors du VLSI 2026.