
IA : installer Ollama, DeepSeek R1 et Open WebUI sur Windows 11 ou Windows Server 2025
Sommaire
I. Présentation
L’intelligence artificielle générative devient de plus en plus accessible, et des solutions open source permettent d’exploiter des modèles de langage en local. Ollama est un outil permettant d’exécuter facilement des LLM en local, sur Windows, Linux ou macOS, tandis qu’Open WebUI fournit une interface web intuitive pour interagir facilement avec ces modèles. Ce tutoriel vous guidera à travers l’installation de ces deux outils sur Windows 11 ou Windows Server 2025.
OpenAI, Google, DeepSeek, Mistral, Anthropic, etc… De nombreuses entreprises proposent des modèles de langage IA avec différentes capacités. Accessibles en tant que solution SaaS, ces intelligences artificielles impliquent aussi de partager des informations avec un tiers. L’utilisation d’Ollama en local peut donc présenter plusieurs avantages :
- Confidentialité : aucune donnée ne quitte votre machine, ce qui est idéal pour échanger sur des données ou documents sensibles. C’est, à première vue, l’avantage principal.
- Disponibilité hors ligne : fonctionne sans connexion Internet.
- Réduction des coûts : pas besoin de payer pour une API cloud, même s’il y a bien entendu le coût de votre matériel et de sa consommation d’énergie.
- Personnalisation : possibilité d’affiner un modèle selon ses besoins (fine-tuning)
Ollama peut être utilisé seul, Open WebUI étant là pour fournir une interface web intuitive (comme l’interface de ChatGPT, par exemple). Nous verrons comment utiliser ces deux outils avec un modèle DeepSeek R1 (proposé par une société chinoise).
II. Performances et choix du modèle
Exécuter un LLM en local n’est pas si évident et vous ne pourrez pas héberger un ChatGPT en local, tout du moins pas avec les mêmes capacités, car vous n’aurez pas la puissance nécessaire. Ollama offre la possibilité d’utiliser en local des modèles de LLM (Large Language Models) et chacun de ces modèles, à une taille indiquée en “B” (milliards de paramètres), correspond au nombre total de paramètres entraînables utilisés dans le réseau de neurones du modèle.
Un paramètre est une valeur numérique (poids ou biais) qui influence la manière dont le modèle génère du texte. Plus il y a de paramètres, plus le modèle a de capacité à capturer des patterns complexes dans les données.
Voici quelques tailles de modèles que vous pourrez rencontrer :
- 1B (1 milliard de paramètres) : modèle léger, adapté aux tâches simples, peu coûteux en ressources.
- 4B (4 milliards de paramètres) : capable de gérer des tâches plus complexes, mais avec encore des limitations.
- 12B (12 milliards de paramètres) : niveau intermédiaire, capable de raisonnements plus avancés et de meilleures performances en NLP.
- 27B (27 milliards de paramètres) : très puissant, proche des modèles d’IA grand public.
Plus le modèle a de paramètres, plus il nécessite de ressources pour fonctionner de façon acceptable. Si vous devez attendre 5 minutes à chaque fois que vous posez une question à l’IA, cela va rapidement vous ennuyer… Tout dépend de votre configuration : avec ou sans GPU, et si GPU, il y a, quelles sont ses capacités.
Certains modèles, en plus de leur capacité qui leur sont propres, peuvent s’avérer aussi plus gourmands en ressources. En mars 2025, Google a lancé ses nouveaux modèles open source Gemma3, basé sur Gemini 2.0 et capable de tourner sur des configurations plus légères.
Remarque : les modèles Gemma sont des modèles LLM open source de Google, tandis que les modèles Gemini sont propriétaires et inclus dans les offres commerciales de Google.
III. Installation d’Ollama sur Windows
A. Téléchargement et installation
Ollama peut être installé facilement sur Windows, soit en téléchargeant le paquet d’installation depuis le site officiel ou à partir de WinGet. Puisque le gestionnaire de paquets WinGet est intégré à Windows 11 et Windows Server 2025, nous pouvons installer Ollama simplement avec cette commande :
En complément de ce qu’il se passe en ligne de commande, un installeur sera visible à l’écran quelques instants. L’installation est automatique.
Quand c’est terminé, fermez la console puis relancez-la de nouveau. Exécutez la commande suivante pour afficher la version d’Ollama, ce qui est l’occasion de vérifier qu’il est bien installé.
La commande est accessible depuis la console Windows (PowerShell ou Invite de commande) car le chemin vers l’exécutable a été ajouté à la variable d’environnement de Windows. Dans le cas présent, l’outil a été installé dans .
B. Ajouter et utiliser un modèle avec Ollama
Actuellement, il n’est pas possible, depuis la ligne de commande, d’obtenir la liste de tous les modèles disponibles dans la bibliothèque d’Ollama. Vous devez consulter directement cette page du site officiel.
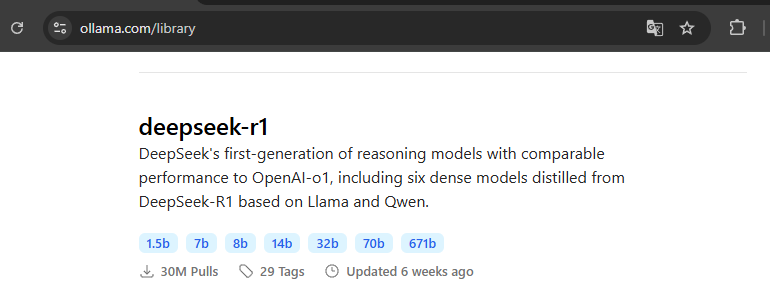
Il y a deux commandes disponibles pour télécharger un modèle :
- télécharge le modèle en local
- exécute le modèle (et le télécharge si nécessaire)
La commande ci-dessous télécharge et exécute par défaut le modèle DeepSeek-R1 7B, dont la taille est d’environ 4,7 Go. Comme son nom l’indique, ce modèle prend en charge 7 milliards de paramètres.
Si tout est correctement téléchargé, Ollama vous permettra d’interagir avec lui. Nous pouvons lui poser une question très simple d’apparence : – Ici, la réponse a été fournie en 2 secondes environ. est un indicateur affiché dans le terminal pendant que le modèle génère une réponse et la réponse finale est retournée cette phase, à la suite de la balise .
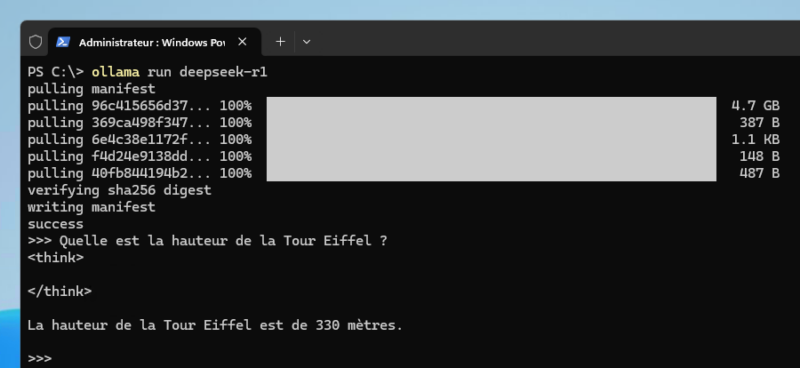
Ici, le modèle répond correctement et de façon très rapide. La même question peut mener à un résultat surprenant, presque surréaliste, où l’IA part dans un ensemble de calculs interminable. Utiliser l’IA en local et lui poser des questions diverses et variées comme on peut le faire sur ChatGPT & consorts, ce n’est pas gagné. Il faut plutôt viser d’autres usages…
Pour quitter la conversation avec l’IA, utilisez cette commande :
Pour installer un modèle avec une taille spécifique, il convient de préciser la taille à la suite du nom. Par exemple, pour obtenir le modèle DeepSeek R1 14B (9 Go d’espace disque), nous utiliserons cette commande :
Ensuite, appelez la commande avec le nom du modèle que vous souhaitez utiliser pour échanger avec l’IA. Interroger le modèle 14B de DeepSeek R1 fait montrer en pression ma machine : 10 Go de RAM consommé par le processus et un processeur Intel Core Ultra 9 185H qui montre à 58% d’utilisation.
Vous pouvez lister les modèles LLM disponibles en local sur votre machine via cette commande :
C. Générer du code avec Ollama
Vous pouvez tout à fait solliciter l’IA pour générer du code, analyser des documents, etc… En fonction de vos besoins. Ci-dessous, la sortie complète brute, telle que présentée dans la console, lors de la sollicitation de l’IA avec l’invite suivante :
Nous verrons par la suite que la sortie est beaucoup plus facilement lisible lors de l’utilisation d’Open WebUI.
IV. Installation d’Open WebUI sur Windows (sans Docker)
A. Installer Open WebUI avec Miniconda 3
Il n’y a pas d’installeur Open WebUI prêt à l’emploi pour Windows. Cette application s’installe en utilisant un conteneur Docker (Docker Desktop sur Windows) ou à partir de l’exécutable proposé sur ce GitHub, ce qui implique d’installer Miniconda (Anaconda) sur sa machine locale en amont. Dans le cadre de ce tutoriel, nous partirons sur l’installation via Minicon, et un autre tutoriel basé sur Docker pour l’ensemble de la stack vous sera proposé par la suite.
Commencez par installer le paquet . Il correspond à Miniconda 3, une version légère d’Anaconda qui permet de gérer des environnements Python et d’installer des paquets via Conda.
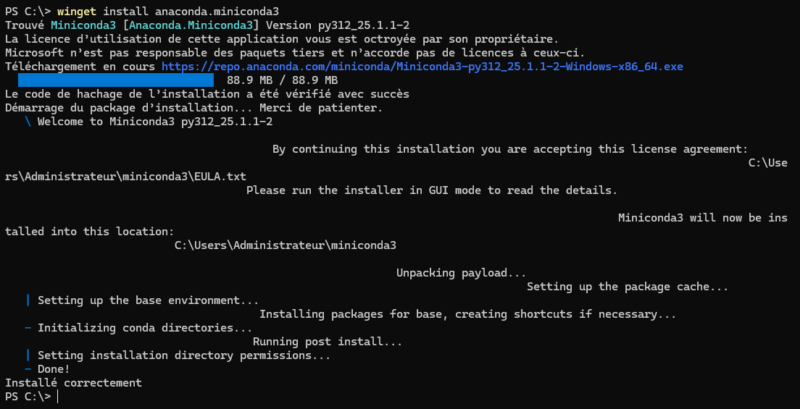
Rendez-vous ensuite sur le GitHub mentionné précédemment pour télécharger le fichier OpenWebUIInstaller.exe. Lancez-le sur votre machine et cliquez sur le bouton “Install“. Vous devez alors patienter le temps de l’installation qui peut nécessiter 10 à 20 minutes selon les performances de votre machine.

Quand c’est terminé, cliquez sur le bouton “Start Open WebUI” et patientez un court instant.

B. Premiers pas avec Open WebUI
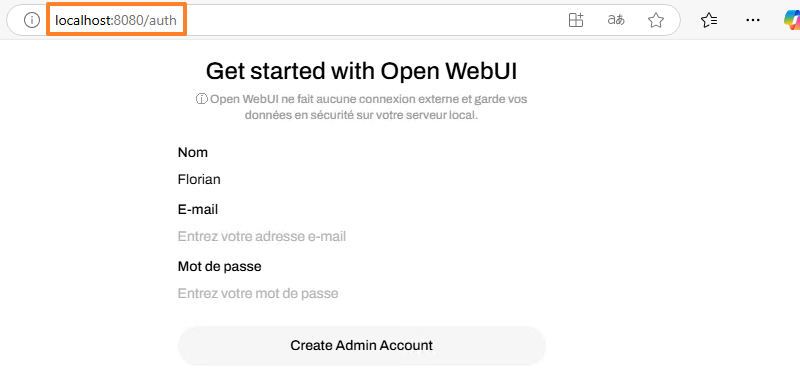
Suite à l’action précédente, Open WebUI va s’exécuter sur votre machine Windows 11 ou Windows Server 2025. Le navigateur va s’ouvrir automatiquement et afficher la page “http://localhost:8080/auth“. Vous devez cliquer sur un bouton pour accéder à la page de connexion, où vous devez créer un compte admin lors de la première connexion.
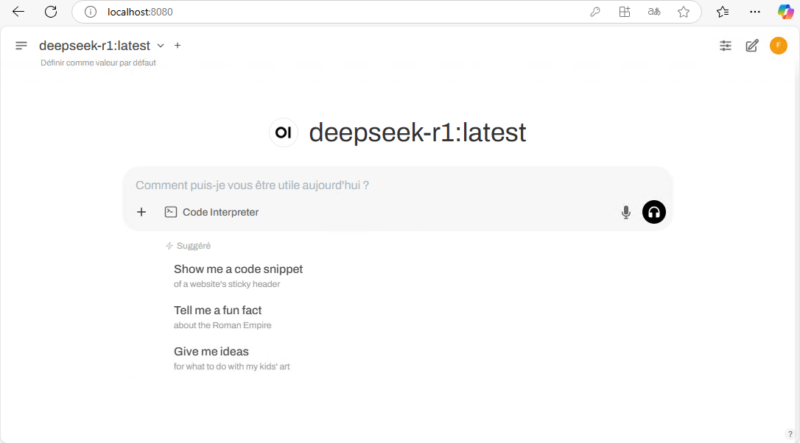
Vous avez alors accès à l’interface d’Open WebUI qui est directement en lien avec Ollama. Cela signifie que les modèles LLM installés précédemment sont déjà accessibles. Vous pouvez passer d’un modèle à un autre en haut à gauche. La zone du milieu vous sert à initier une conversation avec l’IA, que ce soit à l’oral ou à l’écrit.
La phase de réflexion () n’est plus visible, vous verrez le message “En train de réfléchir” à la place. Puis, une fois le traitement terminé, le résultat sera retourné dans l’interface Web et il sera mis en forme grâce au format MarkDown.
L’utilisation de l’IA au travers d’Open WebUI est beaucoup plus agréable que directement avec la ligne de commande Ollama. Comme sur ChatGPT et les autres IA, vous pouvez avoir plusieurs conversations et accéder à votre historique par la suite.
Vous pouvez aussi gérer les modèles à partir de l’interface web. Dans l’exemple ci-dessous, j’ajoute le modèle à mon installation.
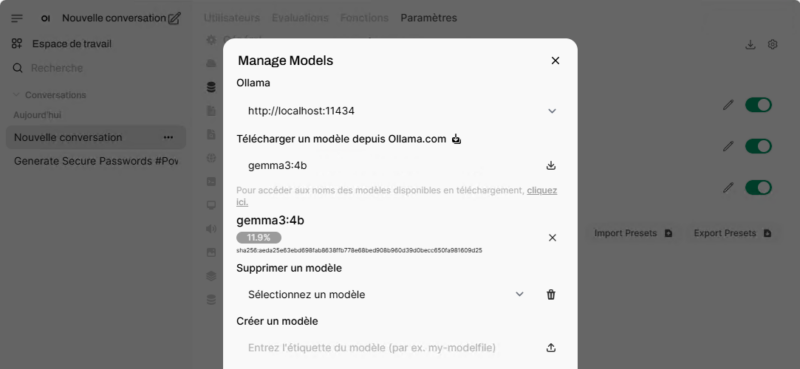
L’interface d’administration donne accès à des fonctionnalités supplémentaires, y compris l’activation de la recherche web. Mais attention, bien souvent il est nécessaire de renseigner des clés d’API pour requêter sur un moteur de recherche. Je dois approfondir mes tests sur cette fonctionnalité, car pour le moment elle ne m’a pas donné satisfaction.
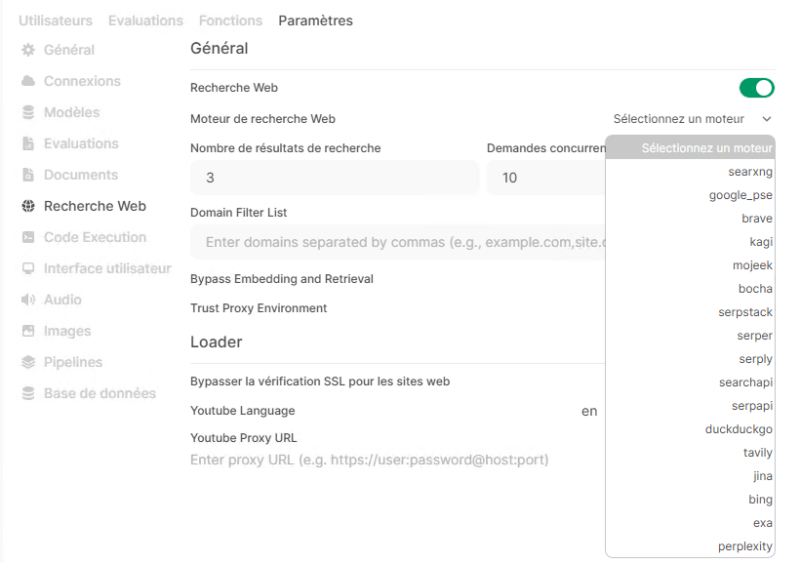
C. L’analyse du code
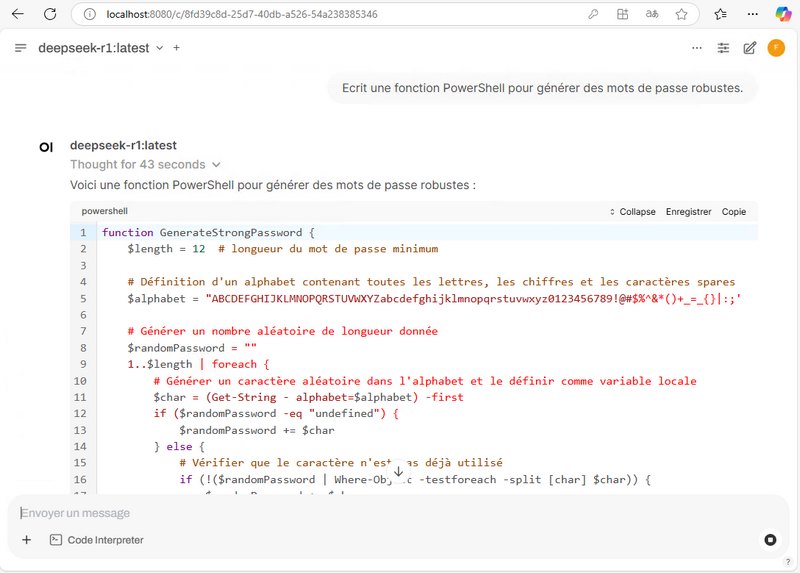
Si vous souhaitez utiliser l’IA pour travailler sur du code, que ce soit pour du debug ou simplement de l’analyse, sans pour autant exposer votre code source, ce type d’installation peut s’avérer utile. Open WebUI intègre d’ailleurs une fonctionnalité nommée “Code Analysis” pour l’analyse de code. Je vous recommande d’utiliser le langage MarkDown pour préciser le type de langage (PowerShell, Python, etc…) et ainsi éviter que l’IA parte dans la mauvaise direction dès le départ….
Cette fonctionnalité donne des résultats assez intéressants. Voici un extrait d’un résultat (non complet) sur une analyse de code basique.
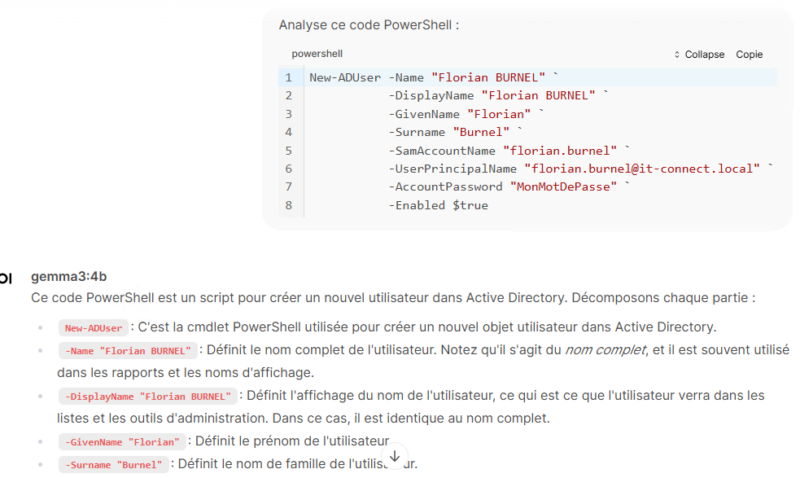
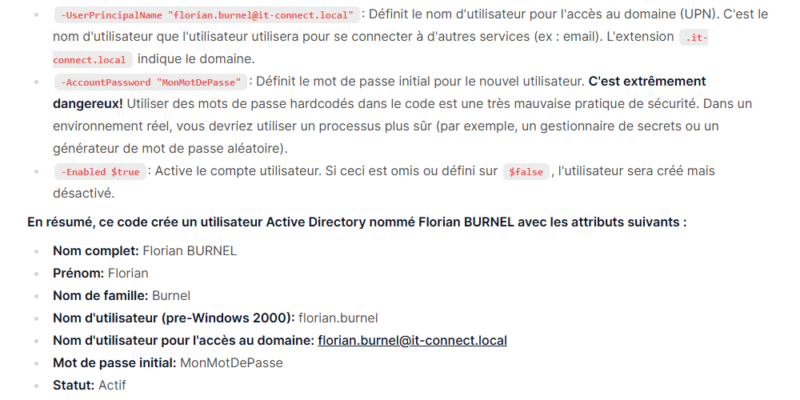
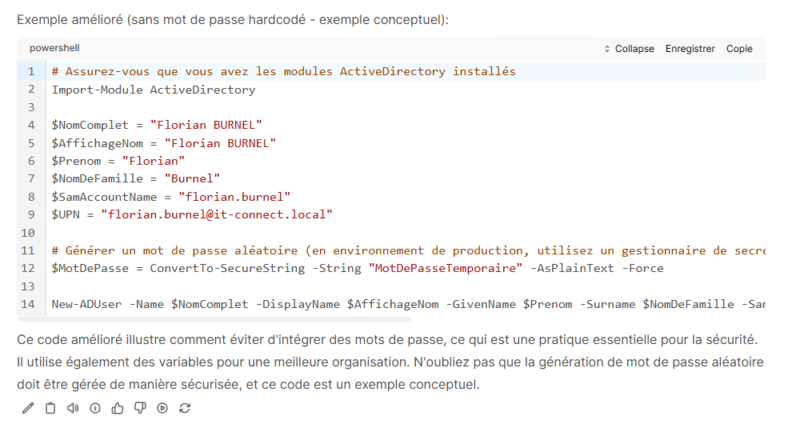
Tout ça, en local, sans exposer aucune donnée et en exploitant les ressources d’un ordinateur standard. Il y a fort à parier que sur les Mac et MacBook équipés d’une puce Apple, les performances soient plus intéressantes.
V. Conclusion
Ollama et Open WebUI offrent une solution simple et efficace pour exécuter des modèles de langage en local. Grâce à cette installation, vous pouvez développer des applications exploitant l’IA sans dépendre des services cloud et sans exposer vos données (c’est probablement le plus important).
En l’état, vous pouvez aussi demander à l’IA d’analyser un document, mais cela ne permettra pas de l’entraîner pour autant. Une évolution intéressante serait justement d’ajouter ce que l’on appelle un RAG (Retrieval-Augmented Generation) pour que le modèle récupère des informations dans des documents avant de répondre. Ainsi, vous pouvez alimenter le modèle avec votre base de documents (les données de votre entreprise, par exemple) et l’interroger par rapport à ces données.
Avec un RAG bien configuré, vous pourriez dire à l’IA : “Analyse ce contrat et dis-moi s’il y a une clause de résiliation.”, le système chercherait alors dans le document, afin d’extraire la clause, puis fournir une réponse précise. À titre d’exemple, vous pouvez regarder du côté de ChromaDB. Il peut s’avérer pertinent aussi d’utiliser des outils comme LangChain et Streamlit pour créer votre propre application capable d’interagir avec l’IA.
C’est un sujet à part entière sur lequel j’effectue des tests de mon côté. Cela pourra faire l’objet d’autres articles. Est-ce un sujet qui vous intéresse ?